This problem uses the table Employee (Id, DeptId, Name, Salary) with primary key Id.
(a) Assume Employee has a clustered index on Id that cannot be changed. It is proposed that
the frequently processed query
SELECT E.Name
FROM Employee E
WHERE E.DeptId = :dept
be handled using index covering. What kind of index would you propose to do this?
Specify the search key attributes and the type (clustered/nonclustered, B+ tree/hash).
(b) If your answer to the previous part was a hash (B+ tree) explain whether a B+ tree (hash)
would work as well.
(c) The application has the following frequently executed queries:
(a) Assume Employee has a clustered index on Id that cannot be changed. It is proposed that
the frequently processed query
SELECT E.Name
FROM Employee E
WHERE E.DeptId = :dept
be handled using index covering. What kind of index would you propose to do this?
Specify the search key attributes and the type (clustered/nonclustered, B+ tree/hash).
Solution:
B+ tree with search key (DeptId, Name), unclustered
(b) If your answer to the previous part was a hash (B+ tree) explain whether a B+ tree (hash)
would work as well.
Solution:
Hash would not work since the search key of the index would have to be (DeptId, Name)
and Name is not known.
(c) The application has the following frequently executed queries:
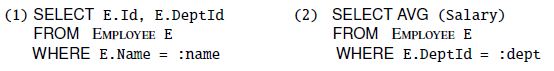
Now assume that the storage structure can be changed, that there are only a few employees
with the same name, and that departments have a large number of employees:
i. What storage structure would you use for the table? If an index is involved state
whether it is a B+ tree or hash, clustered or unclustered.
Solution:
clustered B+ tree (or hash) on DeptId
ii. Describe all additional indexes (don't use index covering). For each state whether it
is a B+ tree or hash, clustered or unclustered.
Solution:
unclustered on primary key Id, could be B+ tree or hash
unclustered on Name, could be B+ tree or hash
iii. Describe the query plan (you hope) the DBMS would use for each query.
Solution:
for query (1) - Hash or search on Name. All index entries corresponding to Name
are either in same bucket or clustered at leaf level. Follow pointers (there are only a
few) to rows with given Name.
for query (2) - Hash or search on DeptId. Scan the bucket or leaf level to get all
rows of employees in the department and take avg. of salaries.
You might also like to view...
The difference between the darkest and lightest area of a picture is the:
a. brightness b. contrast c. recolor
The ________ pane next to a SmartArt graphic is where the content is entered that appears on the shapes used in the graphic
A) Content B) Text C) Smart D) Bullet
The correct salutation for a letter addressed to a company is ____.
A. Dear Company B. Dear Sir C. Ladies and Gentlemen D. To Whom It May Concern
____ technologies require users to sign in with a valid user ID and password to access web-based content such as software programs or e-books.
A. Authentication B. Agile C. Monetized D. Open source