Using an abbreviated version of the 2015 UK Millennium Cohort survey dataset (mcs.dta), perform the following exercises. Note: the survey was carried out in 2015 to 14 year-old pupil in the UK. The dataset consists of nearly 12,000 observations and 52 variables. You need to use the haven package to read-in the data. Perform recoding and labeling on the variables below. Note: for all the variables, you need to first convert them to factors using the as.factor() function.
scien - rename as science and label the values as 1=’1. Strongly Disagree’;2=’2.
Disagree’;3=’3. Agree’;4=’4. Strongly Agree’. This variable includes pupils’ responses to
whether they were good at science.
mcs$scien <- as.factor(mcs$scien)
table(mcs$scien)
1 2 3 4
500 1993 6166 2834
mcs$science <- recode(mcs$scien, "1='1. Strongly Disagree';2='2. Disagree';
3='3. Agree';4='4. Strongly Agree'")
table(mcs$science)
1. Strongly Disagree
500
2. Disagree
1993
3. Agree
6166
4. Strongly Agree
2834
You might also like to view...
Summarizing is a good way to a. begin a relationship with the client
b. close a meeting. c. show the client how much the practitioner knows. d. avoid silence.
Emil Kraeplin compiled ____________________ in order to gain insight into diseases and their outcomes
a. Statistical records b. Symptoms c. Patient self-reports d. Practitioners’ testimonies
The relationship between the variables is significant at what level?
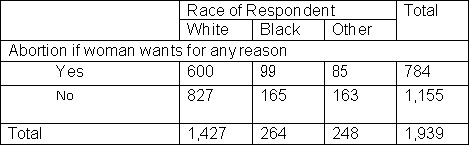
A. 0.001
B. 0.01
C. 0.05
D. 1
Which term best describes the behavioral component of group antagonism?
a. Discrimination b. Bias c. Disparity d. Prejudice